Pour des millions d'entre nous, interagir avec les chatbots d'IA est devenu une routine quotidienne. Nous posons des questions, réfléchissons à des idées, en produisant des e-mails et parfois, peut-être, à sans le savoir, partageant des informations sensibles. Il y a une compréhension tacite que lorsque nous supprimons une conversation, c'est parti pour de bon. Mais une récente ordonnance du tribunal de départ impliquant Openai, la société derrière Chatgpt, a par inadvertance reculé le rideau sur cette hypothèse. Ce développement a révélé une réalité que de nombreux utilisateurs pourraient trouver troublant: l'illusion de la vie privée dans les interactions ou les chats d'IA.
Cette révélation découle d'une bataille juridique à enjeux élevés entre Openai et le New York Times. En 2023, le Times a déposé un procès pour violation du droit d'auteur. L'éditeur a allégué qu'Openai avait illégalement utilisé son vaste mine d'articles protégés par le droit d'auteur pour former ses puissants modèles d'IA. Dans le cadre du processus juridique, un tribunal fédéral a récemment publié une directive radicale: Openai doit préserver indéfiniment les journaux de chaque conversation par Chatgpt, y compris les utilisateurs, pensaient qu'ils avaient supprimé.
L'ordre choquant: la suppression ne signifie pas disparue
Fondamentalement, appuyer sur ce bouton «Supprimer» ne fera pas disparaître vos chats dans l'éther numérique. Eh bien, ils ne seront plus disponibles pour vous, mais ils seront dans la base de données d'Openai. C'est le cœur du COO d'Openai «Nightmare», Brad LightCap, décrit. L'ordonnance du tribunal exige que OpenAI conserve tous les journaux de chat utilisateur et le contenu du client API sans date de coupure. Le juge stipule que la mesure vise à empêcher toute suppression potentielle de preuves pertinentes au différend sur le droit d'auteur. À ce stade, il semble important de se rappeler qu'Openai a admis avoir supprimé accidentellement des preuves potentielles dans le même procès du NYT.
Jane Doe, avocat de la confidentialité de Cybersecure LLP, a déclaré: «Cette directive est sans précédent et établit un précédent dangereux pour l'autonomie des utilisateurs. » « Les entreprises ont besoin de règles claires qui équilibrent les besoins de découverte avec les droits à la confidentialité fondamentale», Ont-ils ajouté.
L'entreprise axée sur l'IA fait appel activement cette décision. La société soutient avec véhémence qu'un tel ordre représente une violation majeure de la confidentialité des utilisateurs. Il entre également directement en conflit avec leurs engagements de confidentialité déclarés. Ils soulignent également l'immense charge technique et logistique de stocker indéfiniment ces ensembles de données colossaux. C'est une escarmouche légale qui est devenue de façon inattendue un «pistolet fumant», exposant les pratiques de collecte de données de l'industrie de l'IA plus larges et remettant en question la notion même de ce que «privé» signifie vraiment à l'ère de l'IA générative.
Inbal Shani, chef de produit chez Github, n'est également pas d'accord avec l'approche de la maintenance indéfiniment des données d'interaction des utilisateurs avec les plates-formes d'IA. « Les données utilisées pour former l'IA ne devraient pas survivre à sa durée de conservation légale ou éthique »,» Elle a dit. «Les organisations ont besoin de systèmes automatisés pour supprimer ou anonymiser les données, en particulier lorsqu'elles sont réutilisées ou réutilisées», A ajouté Shani.
La réalité de la collecte de données: un examen plus approfondi de ce que les chatbots collectent
Si OpenAI est désormais obligé de conserver des chats même «supprimés», cela pose la question: quelle part de nos données ces chatbots AI collectent-ils pour commencer? Bien que l'ordonnance du tribunal soit spécifique à OpenAI dans ce contexte, elle suscite un examen plus large de l'industrie.
Selon des recherches de Surfshark, une entreprise de cybersécurité, le paysage de la collecte de données sur les chatbot AI varie considérablement. Cependant, l'image globale suggère un vaste appétit pour les informations des utilisateurs:
- Meta AI: collecterait les données les plus utilisateur les plus utilisateur parmi les chatbots populaires, recueillant 32 des 35 types de données possibles. Cela comprend des catégories comme un emplacement précis, des informations financières, des données sur la santé et le fitness et d'autres détails personnels sensibles.
- Google Gemini: collecte 22 types de données uniques, qui incluent également des données de localisation précises, des informations de contact, du contenu utilisateur et l'historique de recherche et de navigation.
- ChatGpt (Openai): collecte moins de types par rapport aux autres, à 10 types de données distinctes. Ceux-ci incluent généralement les coordonnées, le contenu des utilisateurs, les identifiants, les données d'utilisation et les diagnostics. Notamment, l'analyse de Surfshark suggère que ChatGpt évite le suivi des données ou l'utilisation de la publicité tierce dans l'application.
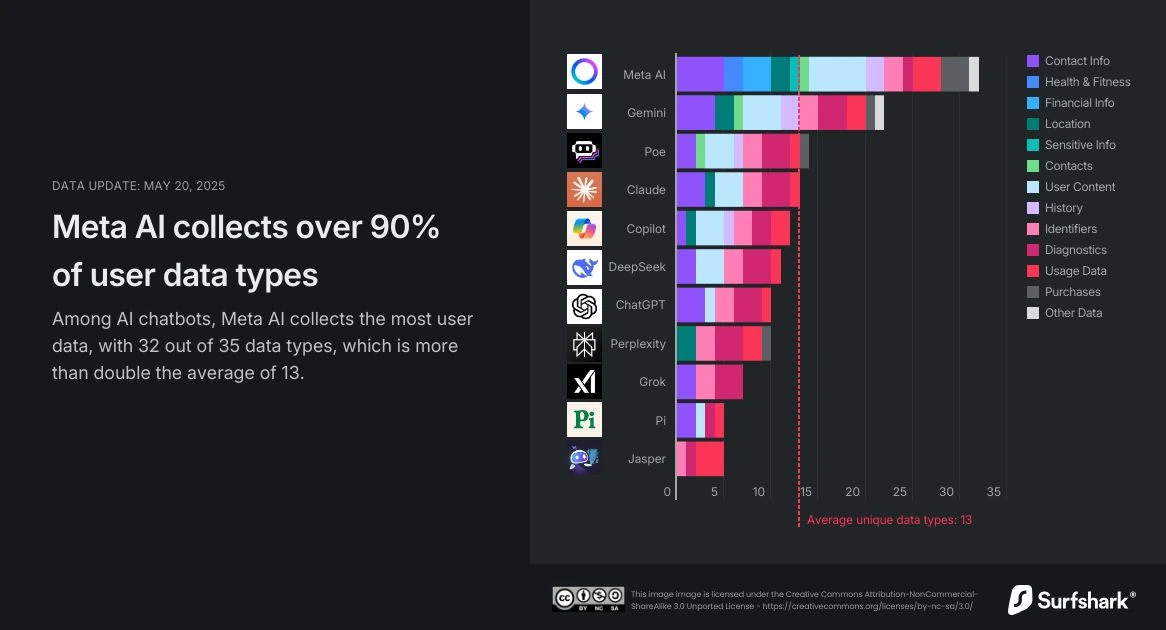
Cette comparaison met en évidence un éventail critique de la collecte de données. Bien que certaines entreprises puissent collecter moins, le volume et le type de données, en particulier les informations sensibles, qui peuvent être associés à vos interactions d'IA sont importantes. Les régulateurs prennent déjà note de cette réalité. Par exemple, le chien de garde de la vie privée d'Italie a récemment giflé la Replika AI avec une amende de 5 millions d'euros pour les violations graves du RGPD liées aux données des utilisateurs. Ces cas mettent en évidence une poussée globale pour une plus grande responsabilité et transparence dans la gestion des données de l'IA.
Un précédent dangereux: éroder la confiance et redéfinir la vie privée
L'ordonnance du tribunal d'Openai établit un précédent dangereux, non seulement pour Openai mais pour toute l'industrie de l'IA. Il brise l'illusion pratique que les conversations utilisateur sont éphémères ou vraiment «supprimées». Pour les utilisateurs, cela signifie que toutes les informations sensibles, pensées personnelles ou requêtes privées partagées avec un chatbot AI peuvent exister indéfiniment sur un serveur. Ainsi, ils pourraient être potentiellement accessibles sous contrainte légale. Cela pourrait conduire à un effet effrayant, où les utilisateurs s'autocenseur ou devenir réticents à s'engager avec l'IA pour des sujets sensibles, sapant l'utilité même et faites confiance que ces outils visent à créer.
Le «privilège» de l'IA de Sam Altman: un appel à la confidentialité
La «peur» de partager des données avec les chatbots d'IA, comme Chatgpt, pourrait également saper la vision d'Openai pour ces types de plateformes. À la lumière de ce paysage de confidentialité, Sam Altman, PDG d'Openai, a exprimé un argument convaincant pour ce qu'il appelle le «privilège de l'IA». Altman estime que les interactions avec l'IA devraient éventuellement être traitées avec le même niveau de confidentialité et de protection que les conversations entre un médecin et un patient ou un avocat et un client. Il a même suggéré le «privilège du conjoint» comme une analogie plus appropriée pour l'intimité de certaines interactions d'IA.
Ce concept n'est pas seulement théorique; C'est une réponse directe aux nouvelles réalités exposées par le procès. L'appel d'Altman au «privilège d'IA» reflète une conscience croissante de l'industrie que les cadres juridiques et éthiques actuels sont mal équipés pour gérer les défis uniques de confidentialité des données posées par l'IA conversationnelle. Il espère que la société aborde cette question rapidement, reconnaissant les implications profondes pour la confiance des utilisateurs et l'utilité de l'IA.
Étapes pratiques que les lecteurs peuvent prendre maintenant
Compte tenu de ces révélations, que pouvez-vous faire pour protéger votre vie privée lorsque vous interagissez avec les chatbots IA?
- Soyez conscient des données sensibles: Évitez de partager des informations personnelles, financières, financières, de santé ou confidentielles très sensibles avec n'importe quel chatbot d'IA. Supposons que tout ce que vous tapez pourrait être conservé.
- Vérifiez les politiques de confidentialité (mais restez sceptiques): les entreprises ont des politiques de confidentialité décrivant la gestion des données. Cependant, n'oubliez pas que les ordonnances judiciaires peuvent obliger la préservation des données, ce qui surestime potentiellement les politiques de suppression standard.
- Utilisez des modes «invités» ou «incognito»: si un service d'IA propose des modes temporaires ou incognito (comme la baisse de l'historique et de la formation de chat de Chatpt), utilisez-les. Comprenez cependant que «temporaire» signifie souvent «supprimé de votre histoire visible», pas nécessairement effacée de tous les systèmes backend.
- Examiner régulièrement les paramètres du compte: vérifiez périodiquement les paramètres de compte de votre chatbot AI pour la rétention des données ou les options de suppression et exercez-les si disponibles.
- Restez informé: gardez un œil sur les discussions sur les nouvelles et la confidentialité autour de l'IA. Le paysage réglementaire évolue rapidement.
Réponses de l'industrie, juridiques et législatives
L'ordonnance du tribunal d'Openai a sans aucun doute envoyé des ondulations dans l'ensemble de l'industrie de l'IA. Bien qu'aucune autre grande entreprise d'IA n'ait annoncé publiquement immédiatement, les changements de politique directs spécifiquement en réponse à cette ordonnance (au-delà des engagements de confidentialité existants), la menace de mandats juridiques similaires conduira presque certainement à des examens internes des politiques de conservation des données et à des efforts de lobbying pour des réglementations plus claires.
Les experts en droit de la vie privée prédisent une examen réglementaire accru. L'Union européenne, avec son RGPD rigoureux (Règlement général sur la protection des données) et la loi sur l'IA pionnière (qui impose un cadre basé sur les risques aux développeurs de l'IA), mène la charge. D'autres nations et régions devraient emboîter le pas. Cela pourrait éventuellement conduire à des lois fédérales de confidentialité fédérales plus complètes aux États-Unis qui abordent spécifiquement l'IA. La bataille juridique elle-même, avec un juge fédéral, autorisant déjà le principal droit de violation du droit d'auteur, devrait façonner l'avenir de la relation de l'IA avec la propriété intellectuelle et les données utilisateur.
L'incident sert de réveil: Bien que l'IA offre une commodité incroyable, le véritable coût des réponses «gratuites» pourrait impliquer une repensation fondamentale de notre vie privée numérique et des référentiels invisibles de nos conversations. Alors que l'IA s'intégère plus profondément dans nos vies, la demande de transparence, des garanties de confidentialité robustes et une compréhension claire de la rétention des données ne feront que se forger plus fort.





